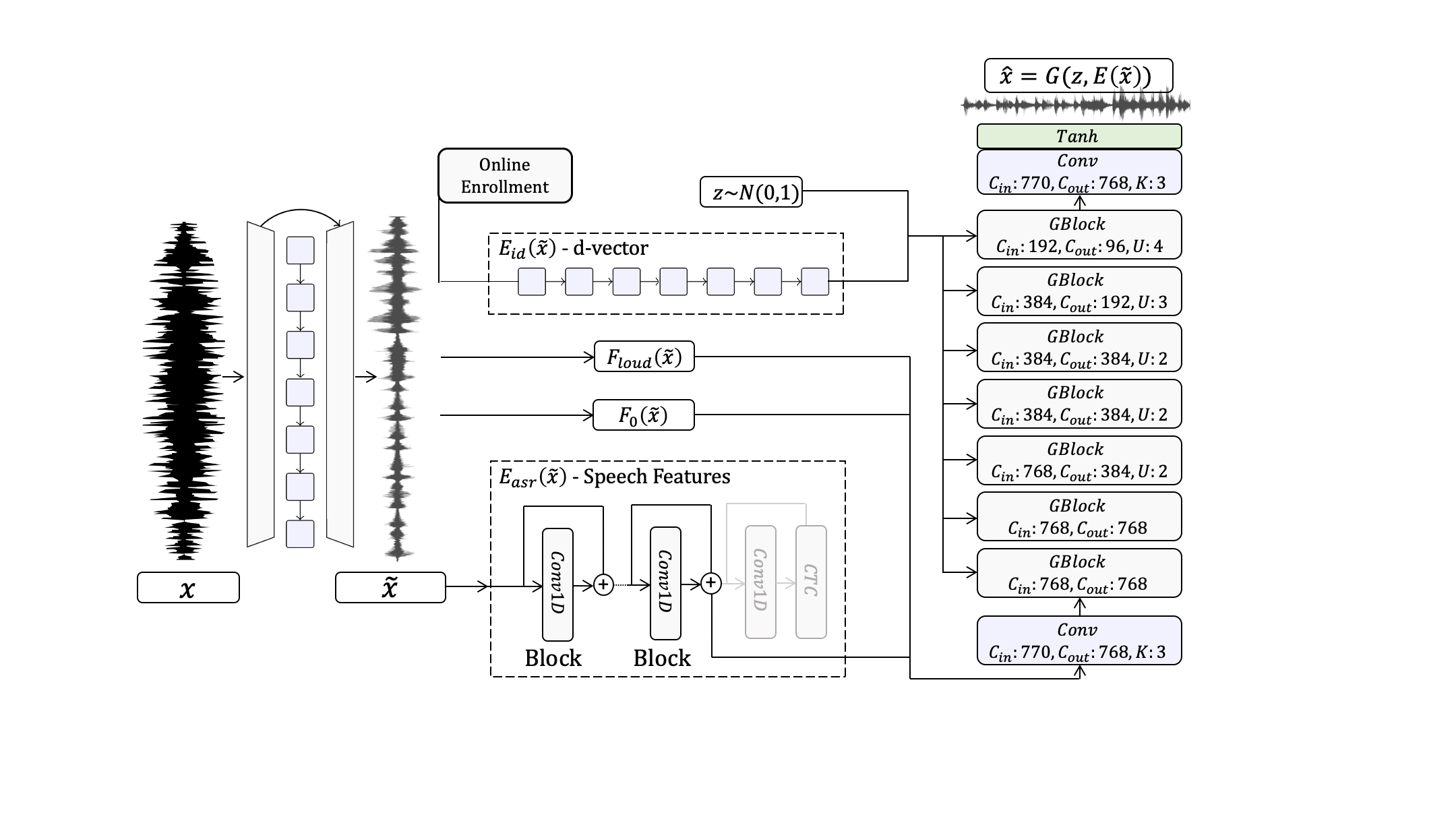
Speech enhancement has seen great improvement in recent years mainly through contributions in denoising, speaker separation, and dereverberation methods that mostly deal with environmental effects on vocal audio. To enhance speech beyond the limitations of the original signal, we take a regeneration approach, in which we recreate the speech from its essence, including the semi-recognized speech, prosody features, and identity. We propose a wav-to-wav generative model for speech that can generate 24khz speech in a real-time manner and which utilizes a compact speech representation, composed of ASR and identity features, to achieve a higher level of intelligibility. Inspired by voice conversion methods, we train to augment the speech characteristics while preserving the identity of the source using an auxiliary identity network. Perceptual acoustic metrics and subjective tests show that the method obtains valuable improvements over recent baselines.